Better Indexes Through Semantic Modeling: A Sketch
Over the past year or so, I’ve been sporadic with my daily journaling practice owing to a number of new note-taking and memory systems consuming my time. As I start getting back into it – because it’s still valuable – I’ve been taking this opportunity to question some of my basic assumptions about the system, which I find valuable once in a while. Since I keep my journal in paper notebooks and transcribing all of them afterwards to allow text searches would be unreasonably time-consuming, I rely on a traditional keyword-based index system to find things later. Is this system the best I can muster?
I don’t think it is. While there’s no doubt it works, it’s not as efficient as it could be, and there are still kinds of navigation I can’t do well – and importantly, I couldn’t do these kinds of navigation even if my journal was in a standard digital format, so this isn’t so much a paper-vs-computers issue as a missing capability in most of our information systems. And I think a better system for indexing my journals could be applied to other types of documents too.
A quick note before we begin: if you’re looking for a completed system you can use by the end of this post, you’re going to be disappointed! I’m working on rapid-prototyping a toy example, but even that isn’t ready yet. Right now I’m hoping to share the idea and see if anyone’s interested in thinking about it themselves or pointing me to existing similar systems I’m not aware of. At some point in the future, if this does turn out to be a good idea, perhaps I’ll have a working system to share.
Existing tools for searching and modeling documents
First, let’s do a quick review of common existing tools in this area. Suppose we have a large document, such as a book, multi-volume historical record, or technical manual or specification document, in front of us. We’re not interested in reading the whole thing; we want to explore just the place or places where a particular topic is discussed within it. How do we go about finding these places?
Full-text search
If we’re on a computer, our first instinct might be to try a full-text search for a phrase we think will be used when discussing the topic. Full-text search is familiar, easy to use, and in the digital world requires little to no effort on the author’s part to make available, so it’s a useful first line of defense.
However, for some kinds of searches we may struggle to find the correct search terms. Better large-scale search engines such as Google can often guess what we mean and return useful results even if we’re sloppy with our search terms, but such search engines use complex proprietary algorithms and are not widely available for individual documents.
Further, when what we’re looking for is vaguely defined, we may be unable to think of appropriate search terms at all, or the ones we think of may return hundreds of results without any obvious way to narrow them down. And once we’ve found one place the topic is discussed, there’s no guarantee that we’ll have any good way to find further related content unless the document author has thought to include cross-references; we’ll have to go back to square one with another search.
So while full-text searches are a useful tool, they aren’t always applicable, and even when they are they’re often a coarse one. They’re excellent for the first stage of discovery (say, picking a couple of relevant documents out of the billions on the web), and they’re excellent when we’re already familiar with the exact spot we’re looking for and just need to jump to it, but for exploration of the document at a level of familiarity between these extremes, they often come up lacking.
Tables of contents and outlines
Most large documents also have tables of contents. These don’t require us to know anything at all about the document to get started, and good ones will introduce us to both the topic and the structure of the document. Few authors will complain if asked to create a table of contents, since it’s usually necessary to do this anyway when working on a large document in order to figure out what one is writing about in what order; further, in modern document preparation systems, it’s usually possible to automatically generate the table of contents from section headings that are already present in the document, making life even easier for the author.
However, if the topic we’re looking for doesn’t have its own section within the document but is rather discussed briefly in many sections across the document, a table of contents is not particularly useful. At best, it will give us a list of places that could be slightly relevant that we can manually scan through to see if they discuss our chosen topic.
An extended version of a table of contents is an outline, which is more or less the same thing but includes much more detail, summarizing the key points of each section. While an outline may help us find topics that are scattered across the document, a good outline of a large work will be sufficiently large that it will be a pain to scan through, and there’s still no guarantee it will capture the topic we’re looking for. Producing an outline is also extra work for the author of the document, so full outlines are rare.
Indexes
An index is an entirely different approach to finding topics. An index is an alphabetical or searchable list of short descriptions of topics we might be interested in, along with the locations in the document where they’re discussed. Indexes transcend the hierarchical limitations of the table of contents and outline; topics can cut across as many sections of the document as necessary, and in principle there is no limit on the number of entries in the index – since it’s arranged alphabetically, even if no electronic searching or filtering is available, we can quickly find a relevant entry even among thousands of other entries, provided we can think of an appropriate keyword to look up.
It’s for these reasons that I’ve always used a keyword index for my journals, which comprise hundreds of thousands of words across dozens of notebooks, are constantly growing, and don’t have much hierarchical structure useful for finding topics. (They’re organized chronologically, but it’s not often that we remember the date on which we discussed a topic – indeed, being able to recover this information is one of the purposes of keeping a journal in the first place!).
However, indexes have some significant issues and limitations:
- They are time-consuming to create and maintain. As they grow, they become even harder to maintain, because it becomes impossible to keep all of the keywords in one’s head, so one will inevitably miss places where a keyword should be used or create multiple keywords that refer to the same thing. If a document is constantly being changed or growing, so that indexing is carried out in short bursts over time rather than all at once, this becomes even harder.
- If the indexer didn’t recognize the topic we’re looking for as one that should be indexed, the index is almost worthless. It’s often difficult to guess what topics will be useful in advance, so this is a major problem, especially when space for storing the index or time for creating it is limited. In the case of an ever-expanding document, it may only become clear that a topic is useful after it’s come up several times, but going back and finding the previous occurrences can be difficult if they haven’t been indexed already.
- Keywords are a rough way of describing topics. It’s not always clear from seeing the keyword whether the section(s) or page(s) mentioned are relevant to our search, and there is no way to know aside from going there and reading them. In dense technical documents, it may take us several minutes to know for sure whether the section is relevant or not if we have to go read it, not to mention the delay if we have to go retrieve a paper copy of part or all of the document first.
- For all the work involved in creating indexes, they don’t actually add any structure to the document. Index entries don’t relate to each other, nor do they appear within the text or create cross-references between sections. They just provide another way of retrieving information when the document’s actual structure has failed to aid retrieval. This seems like a major missed opportunity.
- Indexes are a fundamentally paper-native medium. While they can certainly be used on computers, using them for digital documents, or for searching paper documents using a computer, always feels a little bit silly, like importing typewriter habits to word processing.
Limitations 1 and 2 are, as far as I can tell, inherent to the project of identifying the important aspects of a document and correlating them together, so we won’t be able to fix them. (That said, a good user interface and the model I describe here will reduce the impact of these limitations.) Limitations 3 through 5, in contrast, can be solved by semantically modeling our document – that is, making the index and its user interface aware of the underlying structure of the document, such as its sections and the relationships between topics. In addition, a semantic model will allow us to create special topical tables of contents and search through our documents in arbitrary ways, without doing any more work than we already needed to do to produce the index.
Tabularium: the beginnings of a semantic model
As my journal index has scaled into thousands of entries, I began to need something better than a single index in the front of each volume (at first I could remember what volume something would be in, or take a guess and find it within one or two tries). First I used a simple spreadsheet to aggregate the entries from each volume. Then I wrote a custom application for the purpose, Tabularium. Here’s a screenshot of Tabularium in use to look up references to an event my college choir did every year:
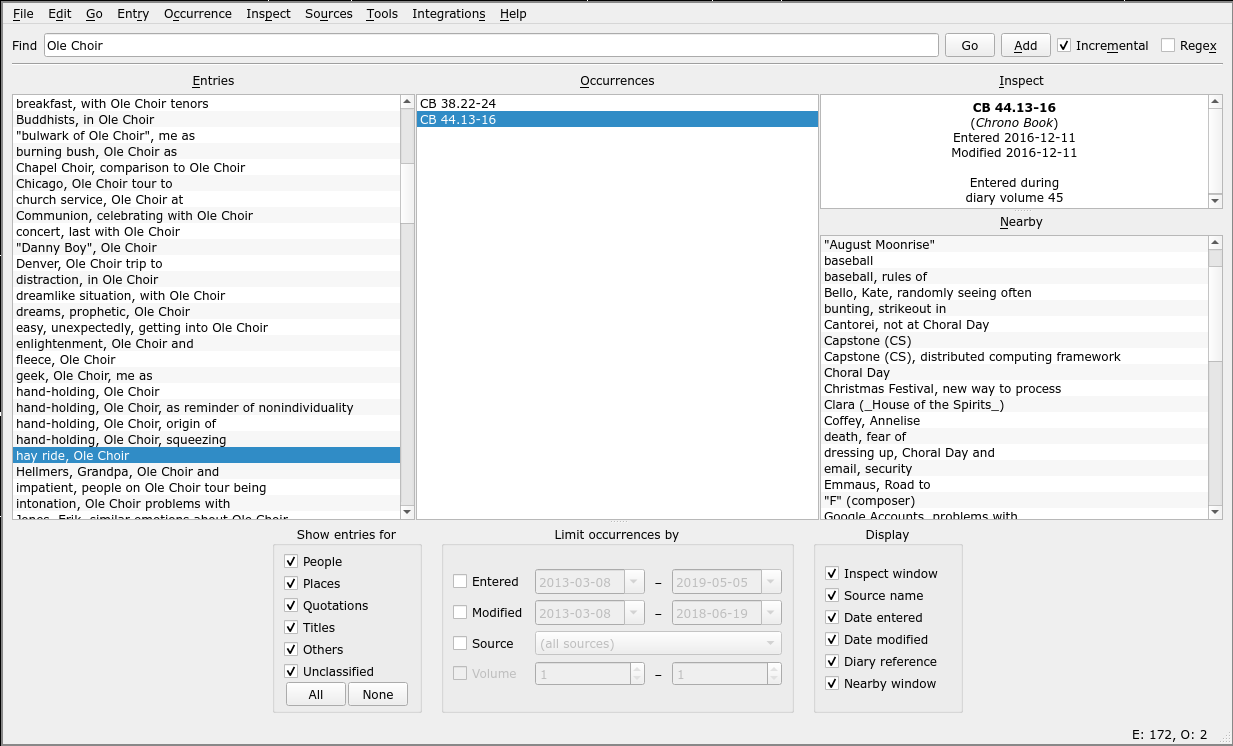
At the top we can use the Find bar to filter the list of index entries. We can select an entry in the left pane to see its occurrences in the middle pane, which define the location where the referenced information can be found (in a “traditional” index, these would be simple page numbers, but since Tabularium can index across multiple volumes and documents, it needs to be a little more sophisticated).
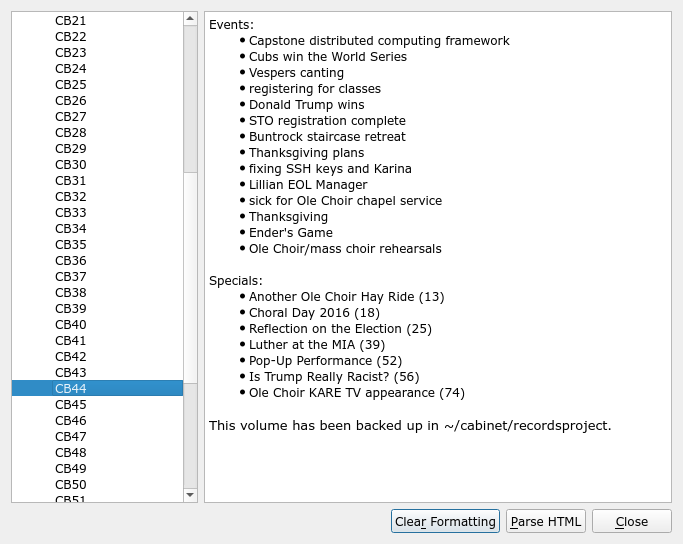
In the right panes, we can see the beginnings of a semantic understanding of the document. In the context of Tabularium’s index model, this means the index is aware of some basic information about how each entry and occurrence is related to the rest of the document. The Inspect pane shows the source and volume the occurrence is found in (in this case, volume 44 of my journal), as well as when we created this occurrence in Tabularium and what diary volume we were in at the time (in this case, that’s not particularly relevant since the source at issue is my journal, but if I was reading and indexing a different book, for instance, I might like to know what else was going on in my life at the time). We can get more details on this volume – mainly, its table of contents – by choosing Inspect → Source Notes:
Beneath the Inspect pane back in the main window, we can see the Nearby pane. This pane looks at the pages surrounding the ones the occurrence points to, works out what other index entries are used on these pages, and displays those entries; we can jump to one of them by double-clicking on it. This feature often allows us to figure out whether the occurrence is relevant to our search without having to go and look in the book. It also often suggests other similar keywords we might wish to look under if we’re still missing some relevant occurrences after looking through all the occurrences of the first entry we found.
The flaws in Tabularium’s model
While Tabularium has been a step in the right direction for me, offering cross-referencing tools that a classic paper index is unable to provide, further improvements are made difficult or impossible by the traditional index model. At this point, I think it’s time to start over and envision what an index would look like if it were a digital-native concept designed to support this kind of semantic model from the start. It doesn’t make sense in 2021 to make our indexes work the same way as those in paper books published in 1900. Often, things we’re indexing nowadays live on the computer already. Even when they don’t, as with my journals, few of us would have a problem with stepping over to the computer or pulling out our smartphones to search for something in a book if it means that search will be far more effective.
Here’s what we can’t do in Tabularium’s keyword-based index model that would be straightforwardly useful (some of these features and use cases overlap):
- We can’t include information within index entries. Returning to the first screenshot, maybe I’d like to see a summary of what the Ole Choir hay ride involves, to make it more clear whether I’ve found the right index entry to be looking under. We could even allow a full-text search in these summaries, so that finding an appropriate index entry wasn’t so dependent on thinking of the single right keyword.
- We can’t build relationships between index entries. We get the automatic “nearby” list based on what index entries point to nearby pages, but if several items are tightly related, it would be nice to make those items surface first in the list of related entries.
- The nearby entries don’t take section boundaries into account. Traditional indexes use page numbers as units of reference, but page numbers normally do not have any relation to the structure of the document: we don’t care whether Section X is on page 56 or on pages 56 and 57 for purposes of determining what it’s related to. Similarly, just because Section Y is also on page 57 does not mean any of its contents are at all relevant to the kinds of information one would be looking for in Section X. We care that an index entry is used in Section X or Section Y, not whether it’s on page 56 or page 57. Notice the irrelevance of many of the nearby entries in the first screenshot above: the rules of baseball are not at all related to a hay ride, nor is All Saints Day; they only happened to be discussed on nearby pages in unrelated sections.
- We can’t build links between sections of the document. Once we’ve found a topic in, say, a journal, it would be nice to be able to jump to previous or future days where similar topics were discussed. Sure, we can implicitly do this by looking through all of the occurrences of a given index entry, but this isn’t always a particularly intuitive way to browse through a document.
- We can’t get hierarchical overviews of the document or see the structure of the document and its index entries in any way other than a list of index entries. With an appropriate semantic model of the document, we can create tables of contents, outlines, indexes, timelines, mind maps, and more, all from a single set of data. For example, currently the table of contents provided in the source overview (second screenshot above) has to be built manually, in an entirely separate step to creating the index. This could be done automatically with this kind of model.
- We can’t explore the document. The index points us to one particular location, and if we want to find other locations, we have to back up and continue our search (just as with a full-text search). A semantic model with appropriate access points can help us find related content that we didn’t even know we were looking for, and embed this information right within the body of the document or a summary thereof.
The vision
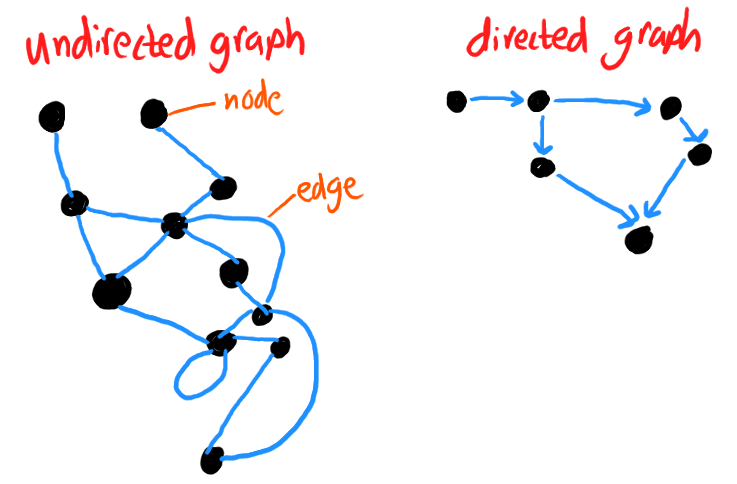
Modern multi-purpose hypertext platforms like TiddlyWiki and Roam Research provide an appealing backbone for semantically modeling documents, at least for a prototype (presumably a purpose-built tool could do a somewhat better job). That’s because what we essentially want to do is to build a graph of the document, in the sense of the mathematical object, and these hypertext systems have such a graph built into their underlying data model, along with tools for exploring the graph.
For anyone not versed in graph theory, here’s a thirty-second introduction which will suffice for understanding this post. A graph consists of nodes (also sometimes called vertices), which are objects to be connected, and edges, which describe which nodes are connected to which other nodes. The edges may be directed (they have arrows attached to them, so that the relationship between the two nodes is asymmetric) or undirected (there are no arrows). In most practical use cases beyond pure mathematics, nodes are understood to contain data of some kind; in a single graph, we might have several different types of nodes storing different types of data. We can also attach data to the edges; for instance, a graph that represents a map of the physical world likely has weights attached to its edges to describe how long or difficult that path between locations is to traverse.
In the following vision, I will occasionally use TiddlyWiki’s terminology and markup language when I want to get more concrete than the mathematical graph model, since I’m most familiar with it and it’s what I’m building my prototype in. TiddlyWiki calls nodes tiddlers and edges links (TiddlyWiki’s fields can also act as edges in some circumstances). But this vision isn’t tied to any technology or platform; it’s the general idea here that counts.
Loci
The most important type of node in the document-modeling system is the locus (plural loci). I choose this deliberately vague term (meaning place in Latin) because the appropriate size of a locus, and the type of division or object within the document that it corresponds to, will vary from document to document. In some documents, a locus might be a paragraph; in others, a subsection; in others, a full section heading. In a journal, it might be a day’s entry; in a video library, one shot or one scene. Since the locus will be the unit of reference – the smallest thing we can point the user of the index directly to – the loci should be small and chosen such that they cut as cleanly between topics or parts of the document’s argument as possible without slicing the document up so finely that the references lose meaning. (As an extreme example of the latter, consider making each word in the document a separate locus. We would then have to index the document word by word, picking the keywords that best described each word. This would be not only laborious but also useless, as individual words ordinarily do not represent whole ideas that can be usefully classified, linked to, or referenced.)
Loci should be chosen based on semantic boundaries in the document, not superficial properties of its physical manifestation like lines, pages, or seconds of footage. If the boundaries between loci could change without affecting the reader’s interpretation of the document, the loci aren’t semantic. (If we make a page of prose narrower so the lines break in different places, the reader won’t care. If we move the paragraph breaks around to random places, she certainly will! So paragraphs are semantic boundaries and lines are not.)
If the document is digital-native, the locus nodes can contain the full text of that locus. If the full text is on paper, in a format that can’t easily be changed or split up such as a PDF, unavailable for remixing due to copyright or other legal or practical issues, or is easier to read when in a different format, the locus can instead contain a concise summary of that unit of the document and a reference to the appropriate location in the full text (for instance, its page number, a section heading, or a URL). If we do have the full text included in each locus, we may want to write a summary anyway and store it along with the full text: this way, we’ll be able to create an outline later and more easily see what parts of the document we’re hopping between.
Loci can contain other arbitrary metadata as name-value pairs (called fields in TiddlyWiki). The types of metadata we want to track will differ depending on the document. For my journal index, I would at a minimum want to track the date the locus was written on and the volume it was included in (although this latter item could be deduced from the date, since I only write in a single volume at a time, moving to the next when I run out of pages). For an index of legal codes, I might want to mention the jurisdiction, the specialty(ies) of law the section applies to, the date it was passed or updated, whether it’s been repealed and by what act, and so on. If the full text is included in the locus and we want to have a summary as well (as discussed in the previous paragraph), we could store the summary as a metadata field. The more information we include now, the more ways we can search through the information in the future and the more views we can create.
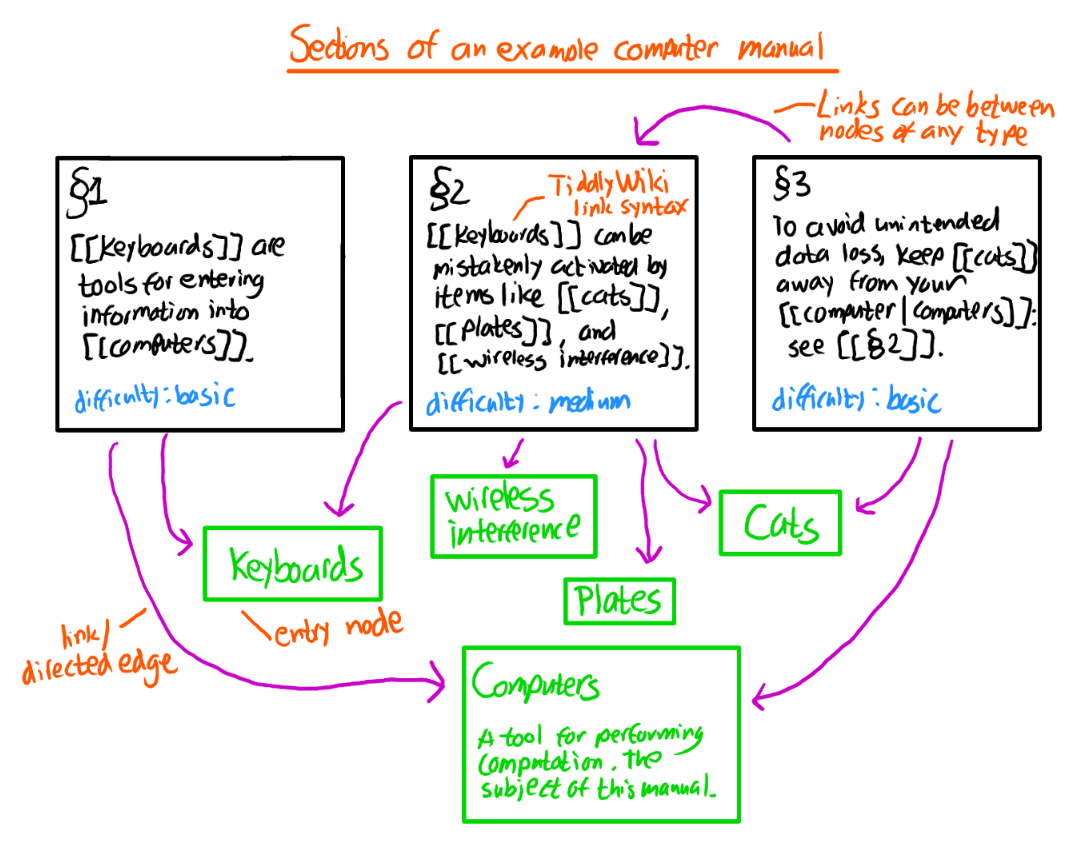
Here’s an example of what our graph might look like after the first three loci of a computer manual:
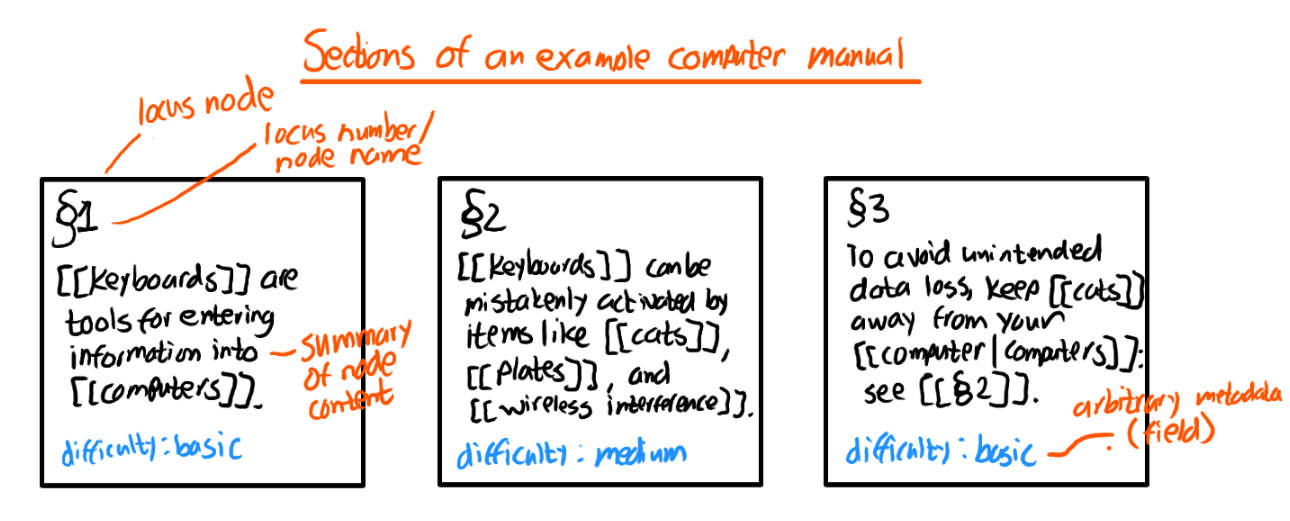
(This isn’t much of a graph yet, as there are no edges. We’ll get there in a moment.)
Note: Users of outline-based hypertext tools might wonder whether it’s really necessary to split the document into loci with hard and fixed boundaries or whether we could instead have a single continuous outline or summary (split into tiny units like sentences or paragraphs, say) and then transclude or link between arbitrary-sized collections of these units, thus creating loci with variable sizes depending on how we’re referencing them. My intuition is that this should be possible but will be a great deal harder to think about and build a useful user interface for, and TiddlyWiki doesn’t natively support such “slicing”, so I’ve chosen to leave it out of my vision for now. Nevertheless, this could be a useful direction for future research.
Entries
In addition to locus nodes, we have entry nodes. These correspond to the typical index entries: keywords, people, places, titles of sources or references, and so on. Entry nodes are connected to locus nodes by edges; in the TiddlyWiki model, they are directed edges, or links, pointing from the locus tiddler to the entry tiddler.
In the summary of a locus tiddler,
we can create a link pointing at an entry node called semantic indexes
by directly writing [[semantic indexes]],
or we can make the link text different than the title of the node it links to,
like [[indexes that understand the shape of the document|semantic indexes]].
Either way, this creates an edge between the two nodes
and establishes the relationship:
one of the subjects discussed in the locus is this particular index entry.
I find this a very natural way to create an index –
as we write our summary (or our full text),
we consider which words and concepts in it
we might want to search on in the future
and toss in the double brackets to make them into links.
TiddlyWiki has several options for autocompleting links
to help us find existing entry nodes where appropriate
rather than accidentally creating duplicate entries
with slightly different wordings.
Entry nodes don’t have to contain any data at all, but they can if we wish: perhaps we want to explain exactly what the keyword is intended to cover or, if it’s a broad topic, provide links to the most important loci, or link to other related index entries.
Here’s what our graph looks like when we create the entry nodes and add the edges created by the links we included in the locus summaries:
Building indexes
Armed with a graph of locus and entry nodes, building a traditional index is easy: we simply retrieve all of the entry nodes, sort them in alphabetical order, and render a link to each of them. In TiddlyWiki, we could render a simple index like this:
<<list-links "[tag[Entry]sort[]]">>
This index isn’t useful quite yet, because when we click the link for an entry, we can’t see what loci it’s associated with, which is the entire point of an index. In TiddlyWiki, we can use a view template applied to all entry tiddlers to list out the loci that link to the current entry tiddler. Our template might look something like:
!! Loci using this index entry
<<list-links "[all[current]backlinks[]tag[Locus]]">>
(The backlinks[] operator follows directed edges backwards from the current node.
links[] follows them forward.)
Building tables of contents
Since we have a semantic model that understands the contents of the document,
we can create an outline just as easily as an index,
using exactly the same data set.
To build an index, we display a list of entries with the loci that refer to them;
to build an outline or table of contents,
we display a list of loci, optionally with their summaries.
A simple TiddlyWiki version, assuming that locus titles are numeric
and sort in the same order we want to show them,
that summaries are no more than one paragraph,
and that the difficulty level of each section of the manual
is stored in the difficulty field of each node as shown in the diagrams above:
<ul>
<$list filter="[tag[Locus]sortan[]]">
<li><$link/> (difficulty level: {{!!difficulty}}) – {{!!text}}</li>
</$list>
</ul>
If we want a multi-level, hierarchical table of contents, we can add another layer of nodes on top of the locus nodes. For instance, suppose our loci are individual paragraphs. We can add a field to each of our loci describing what its “parent” section name is, then add “section” nodes to our graph which aggregate all of their contained loci in order, for instance using:
<<list-links "[tag[Locus]section<currentTiddler>]">>
Then we can similarly create a table-of-contents node that aggregates all of the sections. If we have chapters or parts in our document, we can add additional layers of hierarchy nodes in between. This sounds hard, and in a stock TiddlyWiki it is indeed a bit of a pain, but it doesn’t need to be – as you can see from the code snippets above, the aggregation at each level can be done automatically, and since all of the intermediate nodes are almost exactly the same, they could easily be created automatically as well; all we’d have to do manually is toss in any chapter titles or summaries we wanted to display in the table of contents. A good user interface for this tool would make it fast and easy to add these layers to our index.
Further, we could even choose to create multiple topical or thematic tables of contents, so long as we have the necessary metadata on the loci. For instance, in the legal-code example mentioned earlier, we might build a table of contents of a particular city’s ordinances that shows only the sections applicable to labor law. Or for a large index entry, we could include a table of contents that shows only the chapters and sections of the document that contain at least one locus pointed to by that index entry. The possibilities are essentially limitless.
Nearby lists
We can similarly replicate Tabularium’s Nearby list on loci. On the locus view template, we simply list all of the index entries that are linked within the current locus:
<<list-links "[all[current]links[]tag[Entry]]">>
In fact, this list is more useful than Tabularium’s, because we can show the other index entries that apply to this locus, rather than to nearby pages, which are not semantic boundaries and as such will inevitably capture unrelated entries. Of course, if we wanted to include loci physically adjacent to this one in the document, we could do that, too!
Similarly, we can add a cross-correlated entries list to the entry view template – that is, a list of other index entries that are frequently applied to the same loci as this index entry. To do this, we follow all of the edges backwards from the entry node that lead to locus nodes, then follow all of the edges forwards from each locus node we found that lead to entry nodes, and finally (for neatness) exclude the entry we’re currently looking at:
<<list-links "[all[current]backlinks[]tag[Locus]links[]tag[Entry]!field:title<currentTiddler>sort[]]">>
If we want, we can indicate how many times each entry node is cross-correlated with this one; presumably the entry nodes that appear together with this one more frequently are more likely to be relevant, so we can display those first. I haven’t included that logic because it makes the TiddlyWiki snippet much more complex, but it’s straightforward enough to add features like this.
Arbitrary searches
The user of a semantic model of a document need not be limited to the types of searches envisioned by its author. With the model in place, we can let the user play with the graph directly. The user might, for example, want to do a full-text search on summaries, hop into a particular locus that appears in the results, and list out the index entries that were used on that locus to figure out what else they want to look for. Or they might want to get a list of all journal loci where the events narrated take place in Seattle and include Steve. Just like semantic models can be leveraged to produce different aggregations of the same data, they support dynamic use cases like these which are nearly impossible to support with either full-text search or traditional indexes.
In TiddlyWiki, allowing the user to use filters to search the model can support these use cases. And since TiddlyWikis are editable and can be exported to HTML files and copied around, a savvy user can create her own views in individual tiddlers using code snippets like the ones I’ve shown above and then save them for later reference.
Isn’t it a lot of work to build a semantic model?
In my limited tests so far, no! Or at least, it’s not any more time-consuming than indexing, and it may even be easier cognitively: writing a summary of a section of the text and linking to relevant concepts feels more natural to me than identifying and typing in a bunch of arbitrary keywords associated with it. Indexing is in fact fairly time-consuming, but with a semantic model we get more bang for our buck, so it’s easier to justify taking the time. And if we’ve already decided we want an index, creating a semantic model of the document along the way would seem a no-brainer.
Now, this is a slight lie. I think it has been more time-consuming so far, but that’s only because I’m using a really cruddy prototype with a bad user interface, and I’m competing with an interface I’ve carefully optimized for myself over years. With a fully developed user interface that didn’t require me to take a bunch of extra manual steps to perform straightforward and well-defined operations, I don’t believe it will take any longer, especially if I can also cut out maintaining the table of contents separately.
This said, I should also point out that many documents are too small to justify the work of creating either an index or a semantic model. You shouldn’t bother creating a semantic index of a three-page paper, for instance; quite aside from the time needed for the author to create the index, with such documents, it’s faster to skim the document looking for what you want than to use an index anyway. But for documents that are larger than anyone can easily hold in their head, like full-length books or 6,000-page journals, the semantic model should be a winner.
Isn’t this just…hypertext?
At this point, you might object that the system I’ve described isn’t really an index anymore, or even specifically a means for searching a document – it’s more of a general system for organizing and linking together information that’s really no different than any other hypertext document. To which I would say, yes, it kind of is, at least if the full text of the document is included in the loci. (I’m not aware of any existing systems that are designed to organize only summaries of an external document, though I wouldn’t be at all surprised if there were a couple somewhere.) But I don’t think most people who use hypertext systems currently use them in this way, and even those who do might benefit from thinking about some of their features as indexes or means of retrieving information.
This system would certainly have great potential for integration into other hypertext systems. For instance, I could integrate my journal index into my Zettelkasten and reuse existing idea tiddlers as index entries, making it trivial to find places where I discussed or worked on those ideas in my journal.
Call for prior art
Are you aware of existing systems that sound kind of like what I’m describing?
It’s always possible I’m the first person to have this idea,
but it seems unlikely,
and if there are other similar ideas out there already,
I’d love to hear about them:
it would make further development much easier
and maybe show me some methods that work or blind alleys that don’t.
Please shoot me an email at contact@sorenbjornstad.com
if you know of something.
One mass-market system you may be familiar with that has some of these attributes is Amazon X-Ray. If you aren’t familiar with X-Ray, it’s a really cool contextual information display that works in Amazon streaming video and Kindle eBooks. Opening X-Ray from a particular page or moment in time, you can get information about characters, external references, trivia, and so on relevant to the content you’re currently looking at, and diving into these often lets you find other locations in the source that include the same character or topic. Displaying information like this – and more – on each locus would be easy from a semantic model of the document. And one can see that Amazon must have a model sort of like this of each of their X-Ray enabled books and movies to make the feature work.
(In general: why doesn’t fiction normally have indexes of any kind? Just because the story is organized chronologically doesn’t mean people never want to jump into it at other places or find all the occurrences of a character or place or theme. If you own many fiction books at all, how many times have you pulled a book off the shelf to look for a relevant passage and had to spend 5 minutes leafing through the book to find something that you could have immediately found with an index?)
Conclusion
Existing keyword indexes are an effective tool for finding topics across large documents that can’t easily be aggregated by hierarchical tables of contents or full-text search. But with the widespread use of computers for viewing, searching, and understanding documents, it would appear that creating some simple software tooling would allow authors or indexers to create vastly more searchable and effective document models with little or no additional effort beyond that needed to create a traditional index. Such tooling would support the development of semantic models of documents, ones which represent the underlying structure of the document and model the relationships between parts of the document and topics within it, allowing a wide variety of questions about the document to be answered and the locations of different types of information within it pinpointed in an intuitive way based on this single model. These tools could either be integrated into the experience of reading the document itself or exist in a separate index of the document, as appropriate for each type of document.
I hope this proposal is enlightening to somebody. At the very least, I think I now have a better understanding of what I’m hoping to accomplish. That said, this is likely to be at best a side project in the near future; I don’t have any urgent need for leveling up my indexes, and I have higher priorities. So if this is something you want to try playing with yourself, by all means go ahead!
